参考文章: Towards Deterministic Inference in SGLang
成果
完全确定性的推理,同时兼容 chunked prefill、CUDA graphs、radix cache 和 非贪心采样。
2.8倍的加速,性能开销降低至 34.35% (相比 TML 的 61.5%)。
100% 可复现的强化学习训练
验证确定性行为
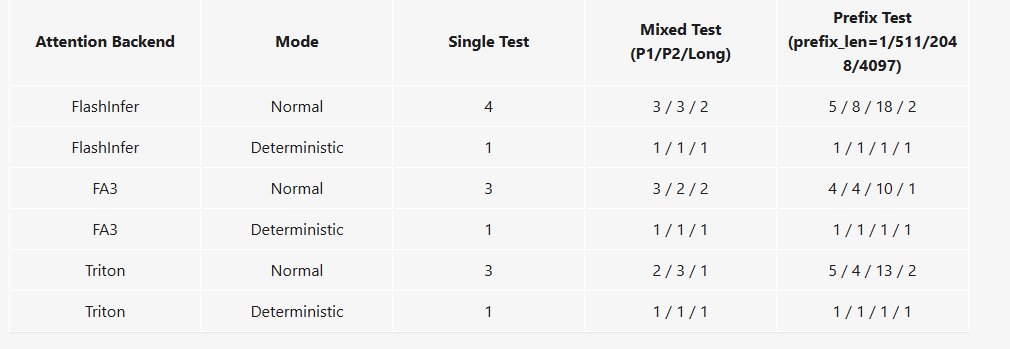
测试类别:
- Single: 在不同批次大小下运行相同的提示。
- 目标: 验证推理结果是否具有 批次不变性 (Batch-Invariant)。
- Mixed: 在同一批次中混合不同类型的提示(短提示和长提示)并验证一致性。
- 目标: 验证不同长度请求的竞争是否影响结果。
- 解释: 长度差异大的提示会显著影响动态批处理调度和 KV 缓存分配。这个测试确保当一个长请求和多个短请求同时运行时,计算资源(如 KV 缓存和 GPU 时间)的复杂分配和管理不会破坏每个独立请求的确定性。
- Prefix: 使用源自同一篇长文本但具有不同前缀长度的提示,将它们随机批处理,并测试结果是否可复现。
- 用例描述: 使用源自同一篇长文本但具有不同前缀长度的提示(例如,使用同一篇文章的前 10 个词、前 511 个词、前 2048 个词作为提示)。将这些不同长度的前缀随机批处理,并测试结果是否可复现。
- 目标: 验证 KV 缓存复用和 Chunked Prefill 机制是否保持确定性。
- 解释: 这个测试模拟了多轮对话或 RAG 场景中常见的上下文共享。它专门针对 SGLang 的 RadixAttention 和 Chunked Prefill 机制。
- Single: 在不同批次大小下运行相同的提示。
测试结果
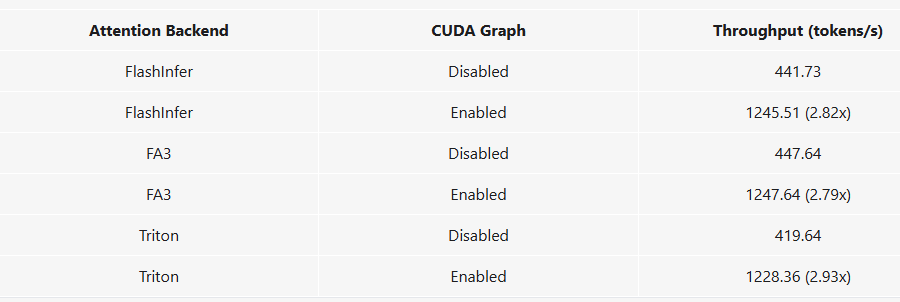
CUDA 图加速
什么是 CUDA Graphs?
- CUDA Graphs 是一种用于捕获和重放 GPU 上一系列操作(称为 内核启动,kernel launches)的机制。
传统 GPU 执行流程(非图模式) 在传统的 CUDA 编程中,GPU 上的每个操作都需要 CPU 发起一个内核启动请求。
- 流程: CPU (主机) → GPU 驱动程序 → GPU (设备)。
- 瓶颈: 每个内核启动都有一定的 CPU 开销(overhead)。对于 LLM 推理,模型生成一个 token 需要进行上百甚至上千个微小的计算操作,CPU 需要为每个操作排队并启动一个内核。在大规模模型中,这些频繁的 CPU-GPU 通信开销会累积起来,成为性能瓶颈。
CUDA Graphs 的机制 CUDA Graphs 通过将整个工作流程视为一个静态图来消除这种启动开销:
- 捕获 (Capture): 在第一次运行时,CUDA 记录下所有的内核启动、内存复制和同步操作,并将它们组织成一个操作图(graph)。
- 实例化 (Instantiate): 驱动程序对这个图进行优化,并准备执行。
- 重放 (Replay): 之后需要执行相同的工作负载时,CPU 只需要发送一个单一的请求来执行整个图,而不是为图中的每个操作发送数百个单独的启动请求。
加速结果
- 至少2.7倍的提升
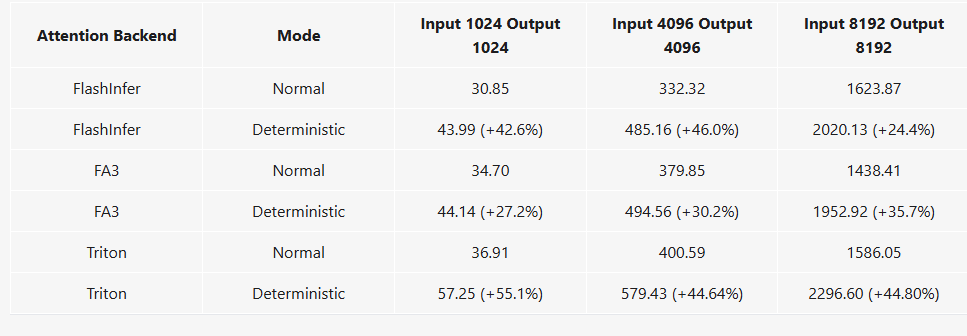
性能问题
Note
Deterministic inference is generally usable, with most slowdowns ranging from 25% to 45%, and average slowdown of FlashInfer and FlashAttention 3 backends being 34.35%.
技术细节
Chunked Prefill (分块预填充)
- 原理: Chunked Prefill 的核心思想是将一个很长的输入序列分割成若干个较小的**块(chunks)**进行处理。
- 交错执行: 推理引擎可以交错执行预填充和解码。在第一个块(chunk)处理完毕后,模型就可以立即开始生成第一个输出 token(解码),而后续的输入块则在后台继续并行处理。
- 主要目的: 降低首个 token 的生成延迟(TTFT)。 通过分块,模型不需要等待整个长上下文预填充完成,极大地提高了用户体验。
**Prefill(预填充)**是指模型在开始生成响应(解码,decoding)之前,处理完整个用户输入(prompt/上下文)并计算出所有的 Key-Value (KV) 缓存的过程。当输入上下文非常长时,这个预填充步骤会很耗时。
与确定性的冲突: 传统的 Chunked Prefill 策略会贪婪地填充当前批次到最大容量。
- Inconsistent truncation points: 取决于批次中其他序列(如 seq_a)的长度。
- 解决方案: align the truncation point with an integer multiple of the split_kv_size.

- 原理: Chunked Prefill 的核心思想是将一个很长的输入序列分割成若干个较小的**块(chunks)**进行处理。
Reproducible Non-Greedy Sampling
- 为了将确定性扩展到贪心解码之外,引入了一个新的采样函数:
multinomial_with_seed。 - 这个修改实现了确定性的多项式采样,同时保留了强化学习 rollouts 所需的随机性。
- 代码链接: sampler.py#L268-L299
- 为了将确定性扩展到贪心解码之外,引入了一个新的采样函数: