Time to First Token (TTFT)
- Definition : How long a user needs to wait before seeing the model’s output.
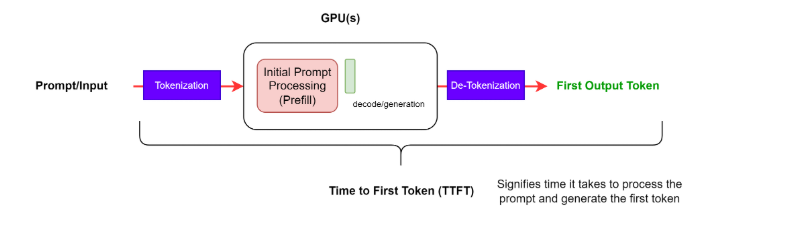
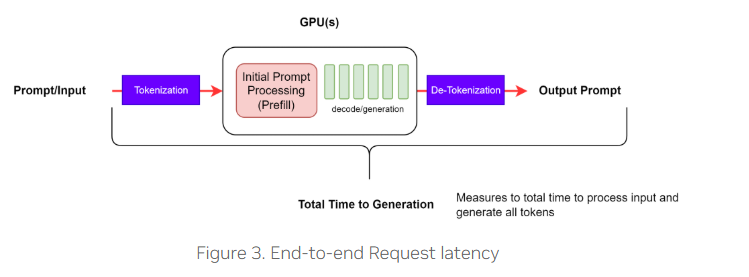
End-to-End Request Latency (e2e_latency)
- Definition : How long it takes from submitting a query to receiving the full response, including the performance of your queueing/batching mechanisms and network latencies
- e2e_latency = TTFT+Generation_time
Inter-token Latency (ITL)
- Definition : `the average time between consecutive tokens and is also known as time per output token (TPOT).

Tokens Per Second (TPS)
- Definition : Total TPS per system `represents the total output tokens per seconds throughput
- As the number of requests increases, the total TPS per system increases, until it reaches a saturation point for all the available GPU compute resources, beyond which it might decrease.
Requests Per Second (RPS)
- Definition : the average number of requests that can be successfully completed by the system in a 1-second period.
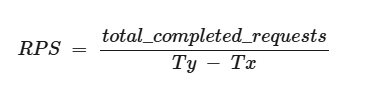
p50/p95/p99 latency
- P99 的值表示99% 的请求都在这个时间值以下完成,只有最慢的 1% 的请求,它们的响应时间会比 P99 的值更长。"
Service-Level Objective (SLO)
- Defines the target performance level for a particular metric.
- For example, an SLO for TTFT might specify that 95% of chatbot interactions should have a TTFT below 200 milliseconds.
- An SLO is typically a key part of a broader service-level agreement (SLA) between a service provider and its users