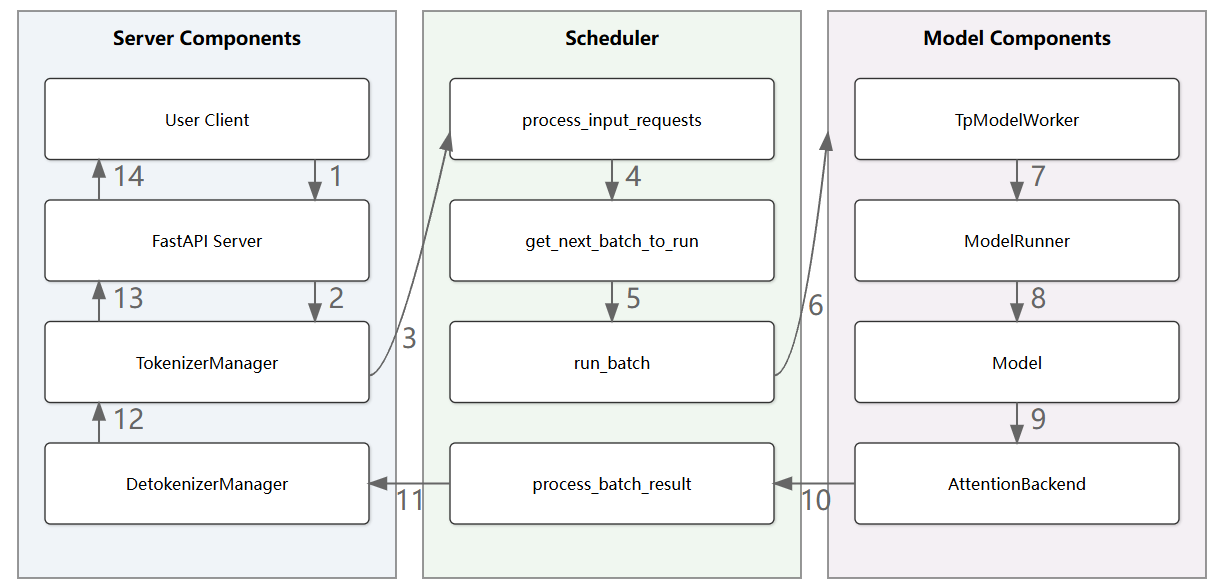
目前主流的 LLM 推理框架主要有三种:VLLM、SGLang 和 LLaMA.cpp。它们各自有不同的设计目标和技术实现,适用于不同的应用场景。
以下内容为本人对其理论基础的理解。
各框架对比
| 特性 | LLaMA.cpp | vLLM | SGLang |
|---|---|---|---|
| 核心优势 | 跨平台兼容性,超高量化效率,CPU/本地推理 | 高吞吐量,最大化 GPU 利用率,单轮服务 | 复杂可编程性,多轮对话 |
| 底层技术/语言 | C/C++(使用 GGML/GGUF/llama.cpp 库) | Python/CUDA(使用PagedAttention、FlashAttention) | Python/CUDA(使用RadixAttention、Compiler-Inspired Design) |
| 内存/KV 缓存 | 使用GGUF格式,支持 CPU/GPU 混合分层 offload;KV 缓存机制相对简单,主要优化单请求/本地运行。 | PagedAttention:内存效率极高,支持高并发动态批处理,减少内存浪费。 | RadixAttention:基于 Radix Tree,擅长动态识别和复用不规则的前缀,优化多轮对话。 |
| 批处理能力 | 较弱(尽管服务器版本支持连续批处理,但性能通常不如 vLLM/SGLang)。**主要优化concurrency=1**的场景。 | 极强(Continuous Batching):最大限度地减少 GPU 空闲时间,实现最高吞吐量(Tokens/秒)。 | 极强(Zero-Overhead Scheduler):支持高并发,尤其在长上下文和多轮任务中表现出色。 |
| 硬件/环境 | 最灵活。支持CPU、GPU(NVIDIA, AMD, Intel)、Apple Silicon (Metal);启动速度极快(几秒)。 | 主要依赖高性能 GPU(CUDA/HIP),启动时间相对较长(分钟级)。 | 主要依赖高性能 GPU(CUDA/HIP),启动时间相对较长(分钟级)。 |
| 模型格式 | GGUF(为其量身定制的量化格式,兼容性好,量化质量高)。 | Safetensors/PyTorch格式,支持 AWQ/GPTQ/FP8 等量化。 | Safetensors/PyTorch格式,支持 AWQ/GPTQ/FP8 等量化。 |
| 典型用途 | 本地运行、嵌入式设备、CPU 推理、快速模型测试、需要灵活量化(如 3-bit, 5-bit)的应用。 | 生产级 API 服务、高并发 Web 部署、需要最大化吞吐量的场景。 | 复杂的 Agent/Chatbot、需要结构化输出(JSON)、多步推理、 |
vLLM
> **核心目标**: 通过 PagedAttention 技术实现最高的吞吐量,最大化 GPU 利用率。
核心理论: PagedAttention
vLLM 对 KV Cache(Key-Value 缓存)的管理进行了革命性的改进。传统 LLM 服务为每个请求分配固定且连续的内存块来存放 KV Cache,这导致了两个主要问题:
- GPU 显存 (VRAM) 的低效利用。
- 吞吐量 (Throughput) 大幅下降,因为会产生大量的内存碎片。
PagedAttention 借鉴操作系统的分页概念来解决这个问题:
- 非连续分配: 它把整个 KV Cache 空间划分为固定大小的块 (Blocks),类似于操作系统中的页 (Pages)。
- 按需分配: 请求不再被分配一个巨大的、连续的内存块,而是按需分配这些小块。
动态分配与挑战
任何空闲的 block 都可以立刻被新的请求使用,从而消除了内存碎片。但这也带来了挑战:Attention 计算必须能够连续地访问请求的 KV Cache 数据。
为解决此问题,vLLM 在软件层面维护一个映射表 (Block Table),记录逻辑 Token 与物理 Block 的对应关系。
| Token Index (逻辑) | Block ID (物理) |
|---|---|
| Token 0 - 3 | Block #5 |
| Token 4 - 7 | Block #12 |
| Token 8 - 11 | Block #30 |
通过查询 Block Table,系统可以从非连续的物理位置获取对应的 KV Cache 数据。
性能飞跃: KV Cache 共享
PagedAttention 实现了高效的 KV Cache 共享。在 Beam Search 或 Speculative Decoding 等场景中,多个输出序列常常在相同的起始文本上扩展。
当多个请求共享相同的前缀时:
- 这些请求的 Block Table 在前缀部分会指向同一组物理 Block ID。
- 系统只需在显存中存储一套前缀的 KV Cache 数据,彻底避免了数据重复复制。
> **写时复制 (Copy-on-Write, CoW)**
当一个共享 Block 需要被修改时,CoW 机制会介入:
- VLLM 为修改请求分配一个新的 Block。
- 将原始 Block 的内容复制到新 Block 中。
- 请求在新 Block 中安全地写入数据,不影响其他请求。
- VLLM 只需更新该请求的 Block Table,将其指向新的 Block ID。
性能总结
- 消除内存碎片: 非连续的 Block 分配 → 动态显存利用 → 大幅提升吞吐量。
- 高效 KV Cache 共享: Block Table 结合 Copy-on-Write (CoW) 机制 → 进一步提升吞吐量,尤其在高并发和复杂解码场景中。
分布式部署
| 特性 | 数据并行 (Data Parallelism) | 模型并行 (Model Parallelism) |
|---|---|---|
| 模型加载 | 每个 GPU加载完整的模型副本。 | 每个 GPU只加载模型的一部分。 |
| 数据处理 | 每个 GPU处理不同的请求数据。 | 单个请求的计算被分解,由所有 GPU协同完成。 |
| 主要目标 | 提升吞吐量。 | 解决显存限制,让超大模型可以被加载。 |
| 通信需求 | GPU 之间几乎没有通信。 | GPU 之间需要频繁通信以传递计算结果。 |
执行循环与 API 服务器
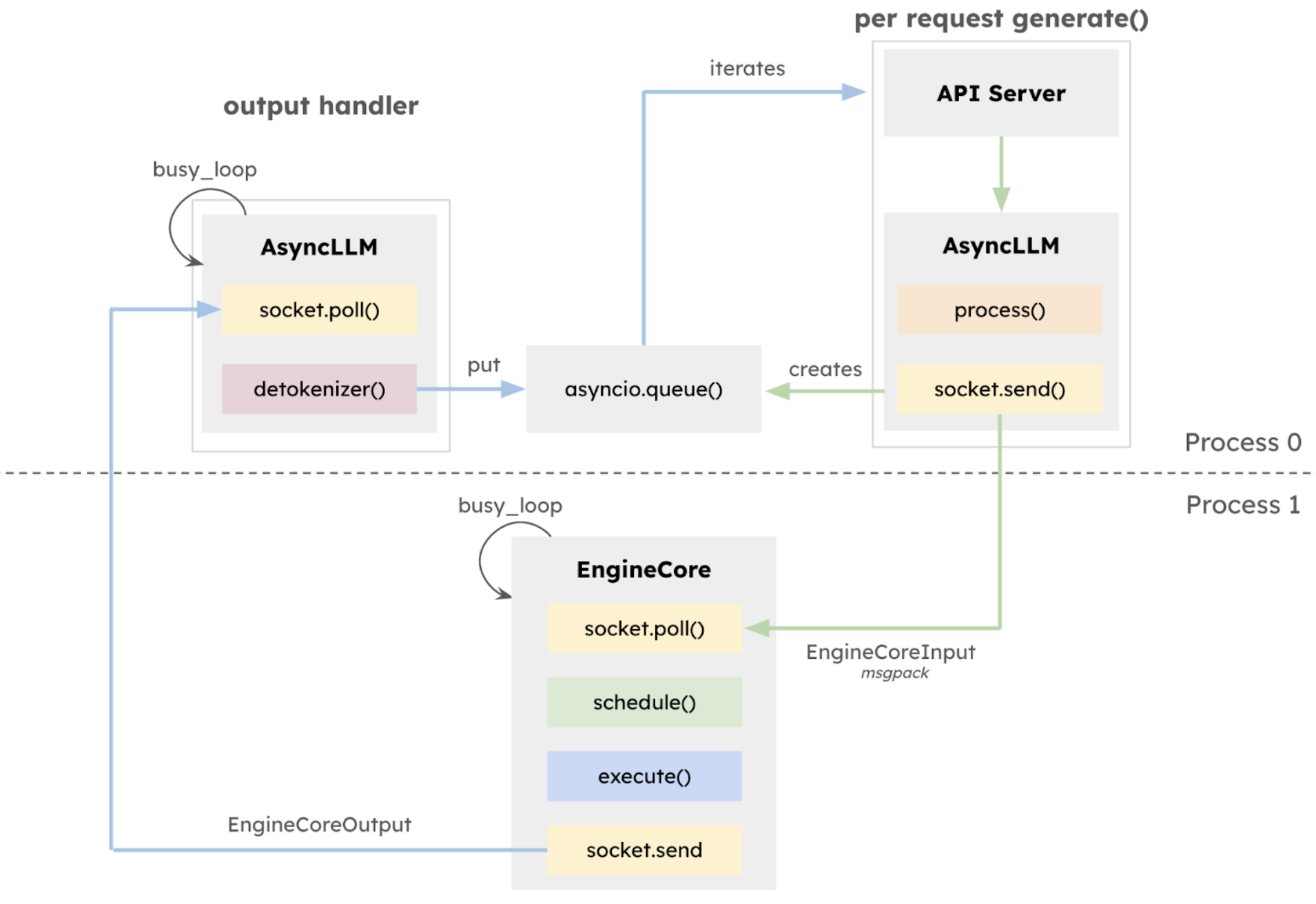
一个推理请求的生命周期: API server → AsyncLLM → EngineCore → ModelRunner → Tokens → API server
- API server: 将请求交给 AsyncLLM。
- AsyncLLM: 对请求进行 Tokenize,然后发送给 EngineCore。
- EngineCore: 调度器对请求进行批处理。
- ModelRunner: 执行器,在 GPU 上运行 Attention 层的正向传播。
vLLM Semantic Router
这是一个为 vLLM 添加意图感知路由层的开源项目,旨在填补 vLLM 在语义决策上的空白。
- 智能路由:
- 简单查询 → 路由到 “快路径” (fast path),实现低延迟和低成本。
- 复杂查询 → 路由到 “Chain-of-Thought” 推理模式,提高准确性。
实验证明,该设计带了约 10% 的准确率提升、50% 的延迟降低和 50% 的 Token 减少。
SGLang
> **核心目标**: 在实现高速度的同时,提供对模型行为的精细控制,尤其擅长处理复杂的多轮对话和结构化输出。
核心理论: RadixAttention
针对长上下文重复计算前缀的问题,SGLang 提出了 RadixAttention,它结合了两种技术:
Radix Tree (基数树):
- 一种空间优化的 Trie 树,用于高效存储和查找共享前缀。
- 自动匹配和共享: 每个节点代表一个 Token。当新请求输入时,系统沿树向下遍历,复用匹配路径上已计算好的 KV 缓存。
- 动态适应: 无论共享前缀多长,Radix Tree 都能灵活处理并自动发现最佳缓存复用点。
零开销 CPU 调度器:
- 优先处理缓存命中率最高的请求以提高计算效率。
- 为避免饥饿问题(请求长时间得不到处理),最终调度优先级由以下因素决定:
- 效率因素: 基于 KV 缓存的命中率/复用率。
- 公平因素: 基于请求的等待时间。
如何控制 LLM 的行为
Python DSL
传统 Prompt Chain 必须串行等待模型响应,效率低下。SGLang 提供了一个 Python 领域特定语言 (DSL),允许在代码中直接控制 LLM 的生成过程。
例如,让 LLM 同时生成中英文摘要:
| 传统 Prompt Chain | SGLang DSL 方式 | |
|---|---|---|
| 执行方式 | 串行 | 并行 |
| 步骤 | 1. 提交“翻译成中文”请求,等待。 2. 提交“翻译成英文”请求,等待。 | 1. 使用 sgl.fork() 同时提交两个翻译请求。2. SGLang Runtime 将请求打包成一个 GPU 批次运行。 |
| 核心机制 | CPU 调度和等待。 | sgl.fork() 原语和 Zero-Overhead 调度器。 |
| 速度 | 总时间 = T中文 + T英文 | 总时间 ≈ T最长任务 |
保证输出格式的可靠性
SGLang 通过有限状态机 (FSM) 在 Token 生成过程中进行强制约束,能 100% 保证 JSON、XML 等格式的正确性。
- 语法检查表: SGLang 将指定的结构化格式(如 JSON Schema)编译成一个 FSM。
- 实时过滤: 在生成每个 Token 前,FSM 会告知模型下一个合法的 Token 集合。
- 强制遵守: SGLang 在模型的 logits 上应用过滤器,强制排除所有不符合 FSM 状态的 Token,从根本上杜绝语法错误。
LLaMA.cpp
> **核心目标**: 提供极致的跨平台兼容性和高效的量化支持,专注于在 CPU 和各类消费级硬件上本地运行。
核心理论: GGUF 格式
GGUF 是 LLaMA.cpp 专门设计的模型文件格式,是其跨平台能力的核心。
- 去 Python 化: GGUF 摆脱了对 Python 和 CUDA 的严重依赖。
- 一站式存储: GGUF 不仅存储模型权重,还打包了所有运行所需的元数据(如分词器
tokenizer、超参数和量化信息)。 - 内存映射友好 (mmap): LLaMA.cpp 可在需要时直接从硬盘加载模型,启动速度极快,并允许将部分模型权重或 KV 缓存分层 offload 到系统内存(CPU RAM),实现 CPU 与 GPU 混合推理。